



Sensei Coup de projecteur sur la bibliothèque : Portée de la bibliothèque


Gérer les dépendances avec souplesse
La fonctionnalité Scope de Sensei a toujours été très appréciée des développeurs. Grâce à la possibilité d'étendre ou de limiter le champ d'application d'une recette, les équipes de développement ont pu adapter son utilisation à des projets individuels et à des secteurs verticaux au sein de leur organisation, ce qui a permis aux développeurs de personnaliser leur expérience.
Elle est donc au centre des processus d'innovation continue de Sensei. Au cours d'une séance de réflexion sur l'innovation visant à élargir le champ d'application du "champ d'application" (oui, c'est un jeu de mots), une question a été soulevée :
"J'essayais de créer une recette pour ... mais depuis la version x, le framework a rendu cette fonctionnalité obsolète. Je ne suis pas sûr qu'il soit encore utile de créer une recette. Qu'en pensez-vous ?"
Bien entendu, ce n'est pas la première fois que nous hésitons à créer une recette. Bien que la recette puisse être considérée comme une information redondante, nous pensons qu'il est utile de créer quelque chose qui s'applique à un nombre limité de versions de la dépendance concernée. C'est pourquoi nous avons créé le champ d'application de la bibliothèque.
La portée de la bibliothèque nous permet de vérifier si une dépendance est présente dans le projet et d'appliquer conditionnellement les recettes Sensei . Cela offre une grande flexibilité lorsque les équipes naviguent dans le code existant et les dépendances.
Beaucoup d'entre vous connaissent l'étendue de la bibliothèque qui est déjà disponible dans les paramètres généraux. Qu'est-ce que c'est, me direz-vous ? Nous avons permis à l'étendue de la bibliothèque d'être présente dans YAML, tout comme la recherche. Cela crée une meilleure expérience utilisateur et n'interrompt pas votre flux lorsque vous créez la recette, ce qui vous obligerait à naviguer vers les Paramètres généraux et à revenir pour mettre à jour les métadonnées. D'autres champs d'application seront intégrés au YAML, mais nous avons commencé par le champ d'application de la bibliothèque.
Voyons donc un peu plus en détail comment cela fonctionne à l'aide d'un exemple.
Portée de la bibliothèque appliquée à hibernate-jpamodelgen
Imaginez le cas suivant :
Nous voulons créer une API Spring Web REST qui nous permette d'interroger certaines données. Conformément aux meilleures pratiques, nous créons un modèle pour l'entité que nous voulons interroger. Ensuite, nous ajoutons une dépendance à l'ORM Hibernate, afin de ne pas avoir à manipuler la structure de la base de données. L'ORM s'en charge pour nous. Nous devons également créer un service qui fournit les données de la couche d'accès aux données (référentiels CRUD, etc.) au contrôleur. Enfin, nous créons la classe du contrôleur pour notre API, où nous exposerons les requêtes autorisées en tant que points d'extrémité.
Pour éviter d'avoir à exposer différents points de terminaison pour chaque champ pouvant être interrogé, nous choisissons plutôt d'utiliser les spécifications JPA 2. Pour ce faire, nous créons une spécification dans le contrôleur à partir de l'URL de la requête. Cette spécification décrit à quoi doivent ressembler les entités que nous recherchons. Dans la classe `Specification` elle-même, nous implémentons la méthode `toPredicate` pour indiquer comment la spécification peut être validée.
Mais nous sommes confrontés à un problème dans la méthode `toPredicate`. Pour construire le prédicat, nous devons connaître les noms des colonnes de la base de données à comparer. Mais comme nous utilisons un ORM, ces colonnes ne sont pas présentes dans un modèle séparé. Le générateur de métamodèle JPA 2 d'Hibernate() vient donc à notre rescousse ! Il vous aidera à générer un métamodèle pour les entités que nous lui avons demandé de gérer. Ces métamodèles nous permettent de référencer les noms de colonnes en tant que propriétés au lieu de les coder en dur.
Création de la recette Sensei
Maintenant que nous avons généré les métamodèles, nous voulons les utiliser à bon escient. Sensei peut aider tous ceux qui travaillent sur le projet en leur rappelant d'utiliser le métamodèle, en s'assurant que les noms de colonnes ne sont pas codés en dur. Mettons donc cela en pratique.
Pour commencer, nous examinons la méthode `toPredicate`:

Ce prédicat de base ne compare que le nom de notre entité. Nous pouvons le développer en utilisant des clauses `et`, mais pour les besoins de cette recette, cette vérification "simple" suffira.
Pour le composant de recherche de la recette, nous voulons appeler la méthode `get()` du paramètre racine, donc nous sélectionnons l'option `methodcall` dans le menu déroulant. Ensuite, nous voulons limiter la recherche à un appel de méthode avec le nom `get` dont la signature est déclarée dans l'interface `Path` du package `javax.persistence.criteria`. Comme la méthode a été surchargée, nous devons également indiquer à la recherche que notre recette ne s'applique qu'à la variante qui prend une seule chaîne de caractères comme argument. Pour résoudre le problème d'avoir les noms de colonnes dans le code, nous voulons utiliser un argument de type `SingularAttribute` à la place, le même type fourni par le générateur de métamodèle.

La recette que nous avons créée jusqu'à présent se déclenchera sur n'importe quelle base de code qui utilise l'interface JPA 2 `Path`, indépendamment du fait que la base de code soit configurée pour utiliser le générateur de modèle Hibernate. Si cette bibliothèque est présente dans le projet, nous voulons indiquer à l'utilisateur qu'elle doit être utilisée, donc nous ajoutons une portée de bibliothèque à la recette.

Enfin, notre recette est prête.

Avec cette recette, toute occurrence de `Path#get` qui utilise une chaîne de caractères comme argument sera signalée. Comme vous pouvez le voir dans l'exemple de code surligné dans la capture d'écran ci-dessus, cette recette fonctionne toujours lorsque le nom littéral de la colonne est stocké dans une variable intermédiaire.
Note - Nous pouvons également inverser la portée de la bibliothèque pour gérer le cas où la bibliothèque n'est pas disponible, en ajoutant une clause `not` à la portée.
Conclusion
Comme nous l'avons vu dans l'exemple ci-dessus, cette nouvelle fonctionnalité nous permet de créer des recettes plus utiles en les appliquant en fonction de la présence de dépendances dans le projet. Pour améliorer encore sa puissance, nous avons inclus plus d'options que celles montrées dans l'exemple, telles que non seulement la vérification de la présence de la dépendance, mais aussi l'application de conditions à la version spécifique de la dépendance.
Les principaux cas d'utilisation que nous voyons pour cette fonctionnalité sont d'empêcher les recettes de fournir des informations en double, de détecter les problèmes liés à des versions spécifiques de dépendances, mais aussi d'effectuer des migrations d'une version de dépendance à l'autre. Nous attendons avec impatience que vous nous fassiez part des utilisations que vous envisagez pour cette fonctionnalité.
Comme pour toutes les fonctionnalités de Sensei , vous trouverez de plus amples informations sur l'étendue de la bibliothèque dans la documentation de référence.
Nick est un chercheur en sécurité dévoué à Secure Code Warrior, avec une expérience à la fois dans l'ingénierie logicielle et la sécurité. Outre sa passion pour la sécurité, il est titulaire d'un Msc. Ir. en sciences informatiques de l'Université de Gand. Il s'est donné pour mission de rendre les logiciels plus sûrs pour nous tous.

Secure Code Warrior est là pour vous aider à sécuriser le code tout au long du cycle de vie du développement logiciel et à créer une culture dans laquelle la cybersécurité est une priorité. Que vous soyez responsable AppSec, développeur, CISO ou toute autre personne impliquée dans la sécurité, nous pouvons aider votre organisation à réduire les risques associés à un code non sécurisé.
Réservez une démonstration


Nick est un chercheur en sécurité dévoué à Secure Code Warrior, avec une expérience à la fois dans l'ingénierie logicielle et la sécurité. Outre sa passion pour la sécurité, il est titulaire d'un Msc. Ir. en sciences informatiques de l'Université de Gand. Il s'est donné pour mission de rendre les logiciels plus sûrs pour nous tous.


Gérer les dépendances avec souplesse
La fonctionnalité Scope de Sensei a toujours été très appréciée des développeurs. Grâce à la possibilité d'étendre ou de limiter le champ d'application d'une recette, les équipes de développement ont pu adapter son utilisation à des projets individuels et à des secteurs verticaux au sein de leur organisation, ce qui a permis aux développeurs de personnaliser leur expérience.
Elle est donc au centre des processus d'innovation continue de Sensei. Au cours d'une séance de réflexion sur l'innovation visant à élargir le champ d'application du "champ d'application" (oui, c'est un jeu de mots), une question a été soulevée :
"J'essayais de créer une recette pour ... mais depuis la version x, le framework a rendu cette fonctionnalité obsolète. Je ne suis pas sûr qu'il soit encore utile de créer une recette. Qu'en pensez-vous ?"
Bien entendu, ce n'est pas la première fois que nous hésitons à créer une recette. Bien que la recette puisse être considérée comme une information redondante, nous pensons qu'il est utile de créer quelque chose qui s'applique à un nombre limité de versions de la dépendance concernée. C'est pourquoi nous avons créé le champ d'application de la bibliothèque.
La portée de la bibliothèque nous permet de vérifier si une dépendance est présente dans le projet et d'appliquer conditionnellement les recettes Sensei . Cela offre une grande flexibilité lorsque les équipes naviguent dans le code existant et les dépendances.
Beaucoup d'entre vous connaissent l'étendue de la bibliothèque qui est déjà disponible dans les paramètres généraux. Qu'est-ce que c'est, me direz-vous ? Nous avons permis à l'étendue de la bibliothèque d'être présente dans YAML, tout comme la recherche. Cela crée une meilleure expérience utilisateur et n'interrompt pas votre flux lorsque vous créez la recette, ce qui vous obligerait à naviguer vers les Paramètres généraux et à revenir pour mettre à jour les métadonnées. D'autres champs d'application seront intégrés au YAML, mais nous avons commencé par le champ d'application de la bibliothèque.
Voyons donc un peu plus en détail comment cela fonctionne à l'aide d'un exemple.
Portée de la bibliothèque appliquée à hibernate-jpamodelgen
Imaginez le cas suivant :
Nous voulons créer une API Spring Web REST qui nous permette d'interroger certaines données. Conformément aux meilleures pratiques, nous créons un modèle pour l'entité que nous voulons interroger. Ensuite, nous ajoutons une dépendance à l'ORM Hibernate, afin de ne pas avoir à manipuler la structure de la base de données. L'ORM s'en charge pour nous. Nous devons également créer un service qui fournit les données de la couche d'accès aux données (référentiels CRUD, etc.) au contrôleur. Enfin, nous créons la classe du contrôleur pour notre API, où nous exposerons les requêtes autorisées en tant que points d'extrémité.
Pour éviter d'avoir à exposer différents points de terminaison pour chaque champ pouvant être interrogé, nous choisissons plutôt d'utiliser les spécifications JPA 2. Pour ce faire, nous créons une spécification dans le contrôleur à partir de l'URL de la requête. Cette spécification décrit à quoi doivent ressembler les entités que nous recherchons. Dans la classe `Specification` elle-même, nous implémentons la méthode `toPredicate` pour indiquer comment la spécification peut être validée.
Mais nous sommes confrontés à un problème dans la méthode `toPredicate`. Pour construire le prédicat, nous devons connaître les noms des colonnes de la base de données à comparer. Mais comme nous utilisons un ORM, ces colonnes ne sont pas présentes dans un modèle séparé. Le générateur de métamodèle JPA 2 d'Hibernate() vient donc à notre rescousse ! Il vous aidera à générer un métamodèle pour les entités que nous lui avons demandé de gérer. Ces métamodèles nous permettent de référencer les noms de colonnes en tant que propriétés au lieu de les coder en dur.
Création de la recette Sensei
Maintenant que nous avons généré les métamodèles, nous voulons les utiliser à bon escient. Sensei peut aider tous ceux qui travaillent sur le projet en leur rappelant d'utiliser le métamodèle, en s'assurant que les noms de colonnes ne sont pas codés en dur. Mettons donc cela en pratique.
Pour commencer, nous examinons la méthode `toPredicate`:
Ce prédicat de base ne compare que le nom de notre entité. Nous pouvons le développer en utilisant des clauses `et`, mais pour les besoins de cette recette, cette vérification "simple" suffira.
Pour le composant de recherche de la recette, nous voulons appeler la méthode `get()` du paramètre racine, donc nous sélectionnons l'option `methodcall` dans le menu déroulant. Ensuite, nous voulons limiter la recherche à un appel de méthode avec le nom `get` dont la signature est déclarée dans l'interface `Path` du package `javax.persistence.criteria`. Comme la méthode a été surchargée, nous devons également indiquer à la recherche que notre recette ne s'applique qu'à la variante qui prend une seule chaîne de caractères comme argument. Pour résoudre le problème d'avoir les noms de colonnes dans le code, nous voulons utiliser un argument de type `SingularAttribute` à la place, le même type fourni par le générateur de métamodèle.
La recette que nous avons créée jusqu'à présent se déclenchera sur n'importe quelle base de code qui utilise l'interface JPA 2 `Path`, indépendamment du fait que la base de code soit configurée pour utiliser le générateur de modèle Hibernate. Si cette bibliothèque est présente dans le projet, nous voulons indiquer à l'utilisateur qu'elle doit être utilisée, donc nous ajoutons une portée de bibliothèque à la recette.
Enfin, notre recette est prête.
Avec cette recette, toute occurrence de `Path#get` qui utilise une chaîne de caractères comme argument sera signalée. Comme vous pouvez le voir dans l'exemple de code surligné dans la capture d'écran ci-dessus, cette recette fonctionne toujours lorsque le nom littéral de la colonne est stocké dans une variable intermédiaire.
Note - Nous pouvons également inverser la portée de la bibliothèque pour gérer le cas où la bibliothèque n'est pas disponible, en ajoutant une clause `not` à la portée.
Conclusion
Comme nous l'avons vu dans l'exemple ci-dessus, cette nouvelle fonctionnalité nous permet de créer des recettes plus utiles en les appliquant en fonction de la présence de dépendances dans le projet. Pour améliorer encore sa puissance, nous avons inclus plus d'options que celles montrées dans l'exemple, telles que non seulement la vérification de la présence de la dépendance, mais aussi l'application de conditions à la version spécifique de la dépendance.
Les principaux cas d'utilisation que nous voyons pour cette fonctionnalité sont d'empêcher les recettes de fournir des informations en double, de détecter les problèmes liés à des versions spécifiques de dépendances, mais aussi d'effectuer des migrations d'une version de dépendance à l'autre. Nous attendons avec impatience que vous nous fassiez part des utilisations que vous envisagez pour cette fonctionnalité.
Comme pour toutes les fonctionnalités de Sensei , vous trouverez de plus amples informations sur l'étendue de la bibliothèque dans la documentation de référence.
Gérer les dépendances avec souplesse
La fonctionnalité Scope de Sensei a toujours été très appréciée des développeurs. Grâce à la possibilité d'étendre ou de limiter le champ d'application d'une recette, les équipes de développement ont pu adapter son utilisation à des projets individuels et à des secteurs verticaux au sein de leur organisation, ce qui a permis aux développeurs de personnaliser leur expérience.
Elle est donc au centre des processus d'innovation continue de Sensei. Au cours d'une séance de réflexion sur l'innovation visant à élargir le champ d'application du "champ d'application" (oui, c'est un jeu de mots), une question a été soulevée :
"J'essayais de créer une recette pour ... mais depuis la version x, le framework a rendu cette fonctionnalité obsolète. Je ne suis pas sûr qu'il soit encore utile de créer une recette. Qu'en pensez-vous ?"
Bien entendu, ce n'est pas la première fois que nous hésitons à créer une recette. Bien que la recette puisse être considérée comme une information redondante, nous pensons qu'il est utile de créer quelque chose qui s'applique à un nombre limité de versions de la dépendance concernée. C'est pourquoi nous avons créé le champ d'application de la bibliothèque.
La portée de la bibliothèque nous permet de vérifier si une dépendance est présente dans le projet et d'appliquer conditionnellement les recettes Sensei . Cela offre une grande flexibilité lorsque les équipes naviguent dans le code existant et les dépendances.
Beaucoup d'entre vous connaissent l'étendue de la bibliothèque qui est déjà disponible dans les paramètres généraux. Qu'est-ce que c'est, me direz-vous ? Nous avons permis à l'étendue de la bibliothèque d'être présente dans YAML, tout comme la recherche. Cela crée une meilleure expérience utilisateur et n'interrompt pas votre flux lorsque vous créez la recette, ce qui vous obligerait à naviguer vers les Paramètres généraux et à revenir pour mettre à jour les métadonnées. D'autres champs d'application seront intégrés au YAML, mais nous avons commencé par le champ d'application de la bibliothèque.
Voyons donc un peu plus en détail comment cela fonctionne à l'aide d'un exemple.
Portée de la bibliothèque appliquée à hibernate-jpamodelgen
Imaginez le cas suivant :
Nous voulons créer une API Spring Web REST qui nous permette d'interroger certaines données. Conformément aux meilleures pratiques, nous créons un modèle pour l'entité que nous voulons interroger. Ensuite, nous ajoutons une dépendance à l'ORM Hibernate, afin de ne pas avoir à manipuler la structure de la base de données. L'ORM s'en charge pour nous. Nous devons également créer un service qui fournit les données de la couche d'accès aux données (référentiels CRUD, etc.) au contrôleur. Enfin, nous créons la classe du contrôleur pour notre API, où nous exposerons les requêtes autorisées en tant que points d'extrémité.
Pour éviter d'avoir à exposer différents points de terminaison pour chaque champ pouvant être interrogé, nous choisissons plutôt d'utiliser les spécifications JPA 2. Pour ce faire, nous créons une spécification dans le contrôleur à partir de l'URL de la requête. Cette spécification décrit à quoi doivent ressembler les entités que nous recherchons. Dans la classe `Specification` elle-même, nous implémentons la méthode `toPredicate` pour indiquer comment la spécification peut être validée.
Mais nous sommes confrontés à un problème dans la méthode `toPredicate`. Pour construire le prédicat, nous devons connaître les noms des colonnes de la base de données à comparer. Mais comme nous utilisons un ORM, ces colonnes ne sont pas présentes dans un modèle séparé. Le générateur de métamodèle JPA 2 d'Hibernate() vient donc à notre rescousse ! Il vous aidera à générer un métamodèle pour les entités que nous lui avons demandé de gérer. Ces métamodèles nous permettent de référencer les noms de colonnes en tant que propriétés au lieu de les coder en dur.
Création de la recette Sensei
Maintenant que nous avons généré les métamodèles, nous voulons les utiliser à bon escient. Sensei peut aider tous ceux qui travaillent sur le projet en leur rappelant d'utiliser le métamodèle, en s'assurant que les noms de colonnes ne sont pas codés en dur. Mettons donc cela en pratique.
Pour commencer, nous examinons la méthode `toPredicate`:
Ce prédicat de base ne compare que le nom de notre entité. Nous pouvons le développer en utilisant des clauses `et`, mais pour les besoins de cette recette, cette vérification "simple" suffira.
Pour le composant de recherche de la recette, nous voulons appeler la méthode `get()` du paramètre racine, donc nous sélectionnons l'option `methodcall` dans le menu déroulant. Ensuite, nous voulons limiter la recherche à un appel de méthode avec le nom `get` dont la signature est déclarée dans l'interface `Path` du package `javax.persistence.criteria`. Comme la méthode a été surchargée, nous devons également indiquer à la recherche que notre recette ne s'applique qu'à la variante qui prend une seule chaîne de caractères comme argument. Pour résoudre le problème d'avoir les noms de colonnes dans le code, nous voulons utiliser un argument de type `SingularAttribute` à la place, le même type fourni par le générateur de métamodèle.
La recette que nous avons créée jusqu'à présent se déclenchera sur n'importe quelle base de code qui utilise l'interface JPA 2 `Path`, indépendamment du fait que la base de code soit configurée pour utiliser le générateur de modèle Hibernate. Si cette bibliothèque est présente dans le projet, nous voulons indiquer à l'utilisateur qu'elle doit être utilisée, donc nous ajoutons une portée de bibliothèque à la recette.
Enfin, notre recette est prête.
Avec cette recette, toute occurrence de `Path#get` qui utilise une chaîne de caractères comme argument sera signalée. Comme vous pouvez le voir dans l'exemple de code surligné dans la capture d'écran ci-dessus, cette recette fonctionne toujours lorsque le nom littéral de la colonne est stocké dans une variable intermédiaire.
Note - Nous pouvons également inverser la portée de la bibliothèque pour gérer le cas où la bibliothèque n'est pas disponible, en ajoutant une clause `not` à la portée.
Conclusion
Comme nous l'avons vu dans l'exemple ci-dessus, cette nouvelle fonctionnalité nous permet de créer des recettes plus utiles en les appliquant en fonction de la présence de dépendances dans le projet. Pour améliorer encore sa puissance, nous avons inclus plus d'options que celles montrées dans l'exemple, telles que non seulement la vérification de la présence de la dépendance, mais aussi l'application de conditions à la version spécifique de la dépendance.
Les principaux cas d'utilisation que nous voyons pour cette fonctionnalité sont d'empêcher les recettes de fournir des informations en double, de détecter les problèmes liés à des versions spécifiques de dépendances, mais aussi d'effectuer des migrations d'une version de dépendance à l'autre. Nous attendons avec impatience que vous nous fassiez part des utilisations que vous envisagez pour cette fonctionnalité.
Comme pour toutes les fonctionnalités de Sensei , vous trouverez de plus amples informations sur l'étendue de la bibliothèque dans la documentation de référence.
Cliquez sur le lien ci-dessous et téléchargez le PDF de cette ressource.
Secure Code Warrior est là pour vous aider à sécuriser le code tout au long du cycle de vie du développement logiciel et à créer une culture dans laquelle la cybersécurité est une priorité. Que vous soyez responsable AppSec, développeur, CISO ou toute autre personne impliquée dans la sécurité, nous pouvons aider votre organisation à réduire les risques associés à un code non sécurisé.
Voir le rapportRéservez une démonstration
Nick est un chercheur en sécurité dévoué à Secure Code Warrior, avec une expérience à la fois dans l'ingénierie logicielle et la sécurité. Outre sa passion pour la sécurité, il est titulaire d'un Msc. Ir. en sciences informatiques de l'Université de Gand. Il s'est donné pour mission de rendre les logiciels plus sûrs pour nous tous.
Gérer les dépendances avec souplesse
La fonctionnalité Scope de Sensei a toujours été très appréciée des développeurs. Grâce à la possibilité d'étendre ou de limiter le champ d'application d'une recette, les équipes de développement ont pu adapter son utilisation à des projets individuels et à des secteurs verticaux au sein de leur organisation, ce qui a permis aux développeurs de personnaliser leur expérience.
Elle est donc au centre des processus d'innovation continue de Sensei. Au cours d'une séance de réflexion sur l'innovation visant à élargir le champ d'application du "champ d'application" (oui, c'est un jeu de mots), une question a été soulevée :
"J'essayais de créer une recette pour ... mais depuis la version x, le framework a rendu cette fonctionnalité obsolète. Je ne suis pas sûr qu'il soit encore utile de créer une recette. Qu'en pensez-vous ?"
Bien entendu, ce n'est pas la première fois que nous hésitons à créer une recette. Bien que la recette puisse être considérée comme une information redondante, nous pensons qu'il est utile de créer quelque chose qui s'applique à un nombre limité de versions de la dépendance concernée. C'est pourquoi nous avons créé le champ d'application de la bibliothèque.
La portée de la bibliothèque nous permet de vérifier si une dépendance est présente dans le projet et d'appliquer conditionnellement les recettes Sensei . Cela offre une grande flexibilité lorsque les équipes naviguent dans le code existant et les dépendances.
Beaucoup d'entre vous connaissent l'étendue de la bibliothèque qui est déjà disponible dans les paramètres généraux. Qu'est-ce que c'est, me direz-vous ? Nous avons permis à l'étendue de la bibliothèque d'être présente dans YAML, tout comme la recherche. Cela crée une meilleure expérience utilisateur et n'interrompt pas votre flux lorsque vous créez la recette, ce qui vous obligerait à naviguer vers les Paramètres généraux et à revenir pour mettre à jour les métadonnées. D'autres champs d'application seront intégrés au YAML, mais nous avons commencé par le champ d'application de la bibliothèque.
Voyons donc un peu plus en détail comment cela fonctionne à l'aide d'un exemple.
Portée de la bibliothèque appliquée à hibernate-jpamodelgen
Imaginez le cas suivant :
Nous voulons créer une API Spring Web REST qui nous permette d'interroger certaines données. Conformément aux meilleures pratiques, nous créons un modèle pour l'entité que nous voulons interroger. Ensuite, nous ajoutons une dépendance à l'ORM Hibernate, afin de ne pas avoir à manipuler la structure de la base de données. L'ORM s'en charge pour nous. Nous devons également créer un service qui fournit les données de la couche d'accès aux données (référentiels CRUD, etc.) au contrôleur. Enfin, nous créons la classe du contrôleur pour notre API, où nous exposerons les requêtes autorisées en tant que points d'extrémité.
Pour éviter d'avoir à exposer différents points de terminaison pour chaque champ pouvant être interrogé, nous choisissons plutôt d'utiliser les spécifications JPA 2. Pour ce faire, nous créons une spécification dans le contrôleur à partir de l'URL de la requête. Cette spécification décrit à quoi doivent ressembler les entités que nous recherchons. Dans la classe `Specification` elle-même, nous implémentons la méthode `toPredicate` pour indiquer comment la spécification peut être validée.
Mais nous sommes confrontés à un problème dans la méthode `toPredicate`. Pour construire le prédicat, nous devons connaître les noms des colonnes de la base de données à comparer. Mais comme nous utilisons un ORM, ces colonnes ne sont pas présentes dans un modèle séparé. Le générateur de métamodèle JPA 2 d'Hibernate() vient donc à notre rescousse ! Il vous aidera à générer un métamodèle pour les entités que nous lui avons demandé de gérer. Ces métamodèles nous permettent de référencer les noms de colonnes en tant que propriétés au lieu de les coder en dur.
Création de la recette Sensei
Maintenant que nous avons généré les métamodèles, nous voulons les utiliser à bon escient. Sensei peut aider tous ceux qui travaillent sur le projet en leur rappelant d'utiliser le métamodèle, en s'assurant que les noms de colonnes ne sont pas codés en dur. Mettons donc cela en pratique.
Pour commencer, nous examinons la méthode `toPredicate`:
Ce prédicat de base ne compare que le nom de notre entité. Nous pouvons le développer en utilisant des clauses `et`, mais pour les besoins de cette recette, cette vérification "simple" suffira.
Pour le composant de recherche de la recette, nous voulons appeler la méthode `get()` du paramètre racine, donc nous sélectionnons l'option `methodcall` dans le menu déroulant. Ensuite, nous voulons limiter la recherche à un appel de méthode avec le nom `get` dont la signature est déclarée dans l'interface `Path` du package `javax.persistence.criteria`. Comme la méthode a été surchargée, nous devons également indiquer à la recherche que notre recette ne s'applique qu'à la variante qui prend une seule chaîne de caractères comme argument. Pour résoudre le problème d'avoir les noms de colonnes dans le code, nous voulons utiliser un argument de type `SingularAttribute` à la place, le même type fourni par le générateur de métamodèle.
La recette que nous avons créée jusqu'à présent se déclenchera sur n'importe quelle base de code qui utilise l'interface JPA 2 `Path`, indépendamment du fait que la base de code soit configurée pour utiliser le générateur de modèle Hibernate. Si cette bibliothèque est présente dans le projet, nous voulons indiquer à l'utilisateur qu'elle doit être utilisée, donc nous ajoutons une portée de bibliothèque à la recette.
Enfin, notre recette est prête.
Avec cette recette, toute occurrence de `Path#get` qui utilise une chaîne de caractères comme argument sera signalée. Comme vous pouvez le voir dans l'exemple de code surligné dans la capture d'écran ci-dessus, cette recette fonctionne toujours lorsque le nom littéral de la colonne est stocké dans une variable intermédiaire.
Note - Nous pouvons également inverser la portée de la bibliothèque pour gérer le cas où la bibliothèque n'est pas disponible, en ajoutant une clause `not` à la portée.
Conclusion
Comme nous l'avons vu dans l'exemple ci-dessus, cette nouvelle fonctionnalité nous permet de créer des recettes plus utiles en les appliquant en fonction de la présence de dépendances dans le projet. Pour améliorer encore sa puissance, nous avons inclus plus d'options que celles montrées dans l'exemple, telles que non seulement la vérification de la présence de la dépendance, mais aussi l'application de conditions à la version spécifique de la dépendance.
Les principaux cas d'utilisation que nous voyons pour cette fonctionnalité sont d'empêcher les recettes de fournir des informations en double, de détecter les problèmes liés à des versions spécifiques de dépendances, mais aussi d'effectuer des migrations d'une version de dépendance à l'autre. Nous attendons avec impatience que vous nous fassiez part des utilisations que vous envisagez pour cette fonctionnalité.
Comme pour toutes les fonctionnalités de Sensei , vous trouverez de plus amples informations sur l'étendue de la bibliothèque dans la documentation de référence.
Table des matières
Nick est un chercheur en sécurité dévoué à Secure Code Warrior, avec une expérience à la fois dans l'ingénierie logicielle et la sécurité. Outre sa passion pour la sécurité, il est titulaire d'un Msc. Ir. en sciences informatiques de l'Université de Gand. Il s'est donné pour mission de rendre les logiciels plus sûrs pour nous tous.
Secure Code Warrior est là pour vous aider à sécuriser le code tout au long du cycle de vie du développement logiciel et à créer une culture dans laquelle la cybersécurité est une priorité. Que vous soyez responsable AppSec, développeur, CISO ou toute autre personne impliquée dans la sécurité, nous pouvons aider votre organisation à réduire les risques associés à un code non sécurisé.
Réservez une démonstrationTéléchargerRessources pour vous aider à démarrer
Viser l'or : La montée en puissance des normes de code sécurisé chez Paysafe
Découvrez comment le partenariat de Paysafe avec Secure Code Warrior a permis d'augmenter de 45 % la productivité des développeurs et de réduire considérablement les vulnérabilités du code.

.png)
Le pouvoir de la marque dans l'AppSec DevSec DevSecOps (Qu'y a-t-il dans un acrynème ?)
Dans le domaine de l'AppSec, l'impact durable d'un programme exige plus que de la technologie : il faut une marque forte. Une identité forte garantit que vos initiatives trouvent un écho et suscitent un engagement durable au sein de votre communauté de développeurs.
Trust Agent : AI by Secure Code Warrior
Ce document présente le SCW Trust Agent : AI, un nouvel ensemble de fonctionnalités qui fournissent une observabilité et une gouvernance approfondies sur les outils de codage de l'IA. Découvrez comment notre solution établit une corrélation unique entre l'utilisation des outils d'IA et les compétences des développeurs pour vous aider à gérer les risques, à optimiser votre SDLC et à garantir que chaque ligne de code générée par l'IA est sécurisée.
.avif)
Vibe Coding : Guide pratique pour la mise à jour de votre stratégie AppSec pour l'IA
Regardez à la demande pour apprendre comment permettre aux responsables AppSec de devenir des facilitateurs de l'IA, plutôt que des bloqueurs, grâce à une approche pratique, axée sur la formation. Nous vous montrerons comment tirer parti de Secure Code Warrior (SCW) pour actualiser votre stratégie AppSec à l'ère des assistants de codage IA.
Ressources pour vous aider à démarrer


Pourquoi le mois de la sensibilisation à la cybersécurité doit-il évoluer à l'ère de l'IA ?
Les RSSI ne peuvent pas s'appuyer sur le même vieux manuel de sensibilisation. À l'ère de l'IA, ils doivent adopter des approches modernes pour protéger le code, les équipes et les organisations.
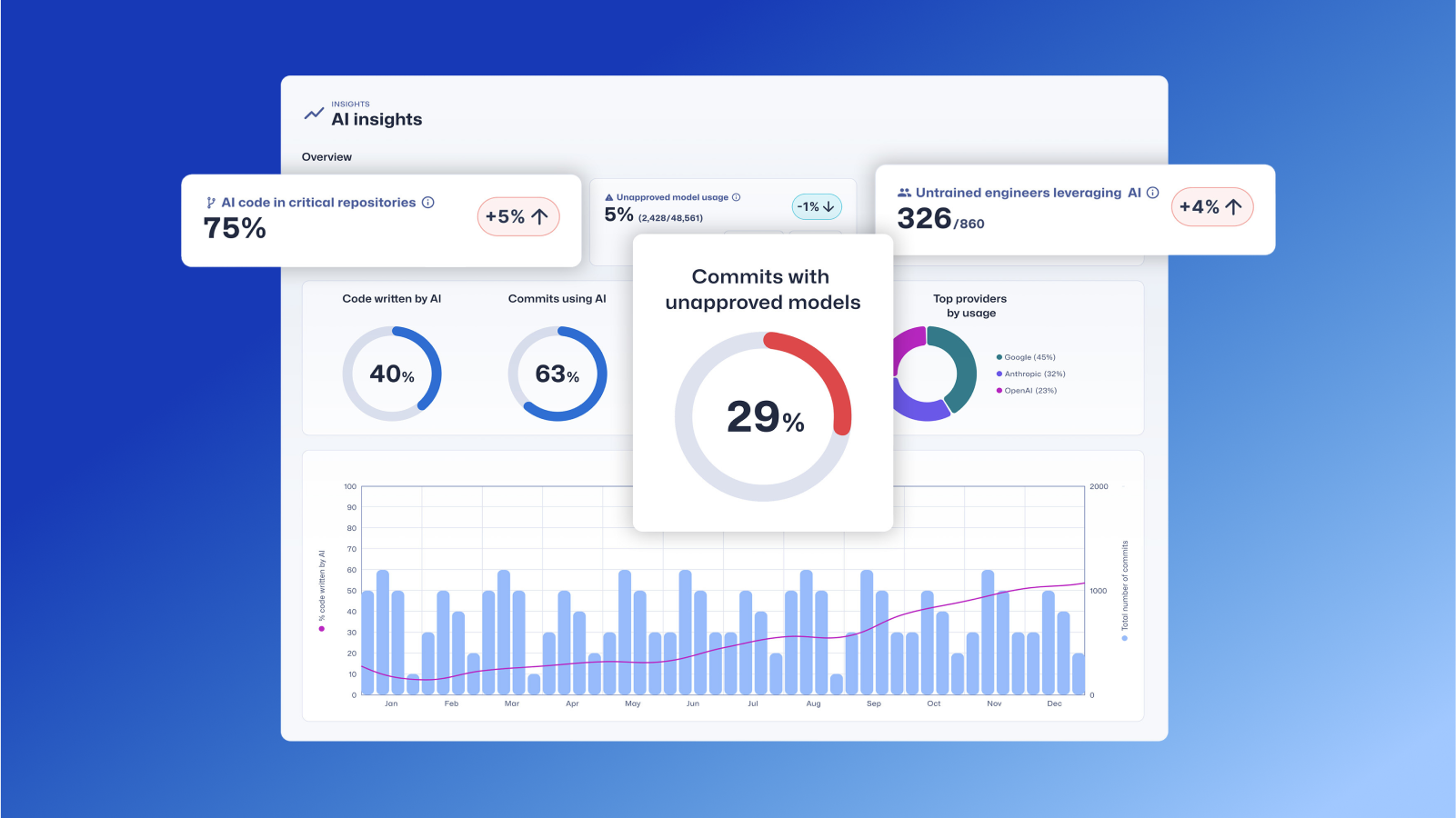
SCW Trust Agent : AI - Visibilité et gouvernance pour votre SDLC assisté par l'IA
Découvrez comment Trust Agent : AI offre une visibilité et une gouvernance approfondies sur le code généré par l'IA, ce qui permet aux entreprises d'innover plus rapidement et de manière plus sécurisée.
.avif)
Codage sécurisé à l'ère de l'IA : essayez nos nouveaux défis interactifs en matière d'IA
Le codage assisté par l'IA est en train de changer le développement. Essayez nos nouveaux défis IA de type Copilot pour réviser, analyser et corriger le code en toute sécurité dans des flux de travail réalistes.
Codage axé sur le développeur.
En toute sécurité.
Contactez-nous dès aujourd'hui et faites de la sécurité des logiciels une partie intrinsèque de votre processus de développement.
